Manuel d'utilisation du module Assistants IA pour Dolibarr
18 minutos de lectura
Ce module, que vous pouvez acheter sur Dolistore, vous offre la possibilité d'utiliser de nombreux modèles d'IA générative directement depuis votre propre Dolibarr, en consommant le minimum via les API des différents fournisseurs, au lieu de souscrire à des abonnements mensuels fixes pour chaque employé de votre entreprise.

Index
Si vous n'êtes pas un utilisateur administrateur de votre Dolibarr, vous pouvez passer au point 3 de ce manuel.
- Processus d'installation
- Intégration avec les fournisseurs d'IA
- OpenAI (génération de texte)
- Anthropic.com (génération de texte avec vision)
- Perplexity (gén. de texte et recherche sur internet)
- Fal.ai (gén. d'images avec FLUX et StableDiffusion)
- Converser avec une IA
- Prochainement
- Accès à DEMO
1. Processus d'installation
Tout d'abord, comme d'habitude pour l'installation de tout module Dolibarr :
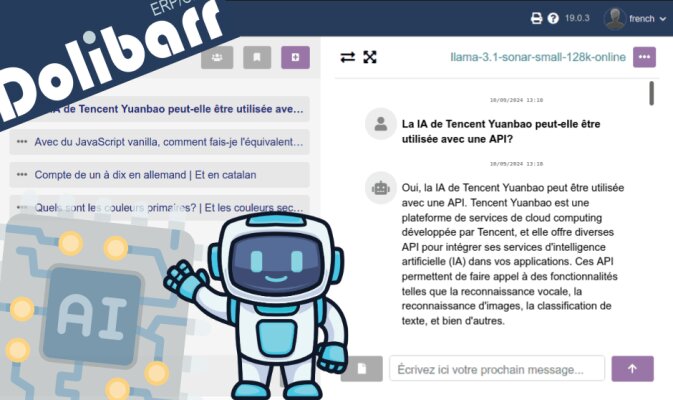
- Allez à la section Configuration
- Allez à Modules
- Allez à l'onglet Installer un module externe, et là vous téléchargez le ZIP du module ou sa mise à jour
- Revenons à l'onglet Modules disponibles
- Filtrons par Origine : "Externe - IMASDEWEB"
- Activons le module
- Cliquons sur l'icône de Configuration
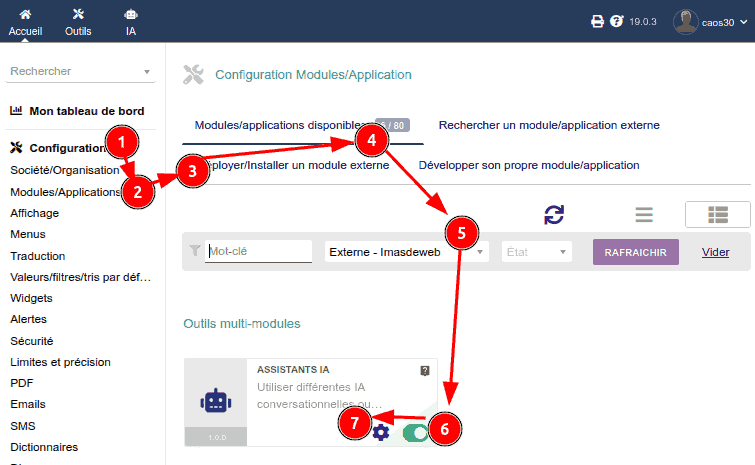
Dans une première section Divers, nous pouvons configurer des choses comme le "Modèle par défaut". Ce sera le modèle avec lequel un chat sera initialisé lorsque le système n'a pas d'information dans la variable de session de l'utilisateur sur le dernier modèle qu'il a utilisé.
Limite d'utilisation par utilisateur
Vous pouvez configurer la limite d'utilisation par utilisateur, aussi bien par heure que par jour :
- Chaque fois qu'un utilisateur fait une demande d'IA, le système compte combien de demandes il a faites au cours des 60 dernières minutes, et aussi au cours des dernières 24 heures. Et si l'une de ces valeurs dépasse la limite correspondante, alors il affiche un message à l'utilisateur l'encourageant à réessayer plus tard.
- Selon la taille de votre organisation et le type d'utilisation que vos utilisateurs/employés feront ou ont besoin de faire, il vous conviendra de configurer ces deux paramètres différemment.
Par exemple, peut-être que vous ne voulez pas qu'un utilisateur puisse faire une utilisation très intensive de l'IA (générant des textes, des images, etc.) pendant quelques heures. Vous pouvez alors configurer une limite horaire élevée (par exemple, une demande toutes les 10 secondes serait 6 par minute et 360 par heure. Mais comme vous ne voulez pas que cela encourage une utilisation excessive, vous pourriez fixer une limite de seulement 1400 toutes les 24 heures. De cette façon, vous permettriez des utilisations intensives de l'IA, tout en garantissant un certain contrôle sur une utilisation abusive prolongée.
2. Intégration avec les fournisseurs d'IA
C'est la partie la plus intéressante et qui variera le plus fréquemment avec chaque mise à jour. Au cours des prochains mois, de plus en plus d'intégrations avec de nouveaux fournisseurs ou de nouveaux modèles des mêmes fournisseurs seront ajoutées. Donc, si vous voulez en tirer le meilleur parti, il serait recommandé de mettre à jour régulièrement.
Pour configurer chaque fournisseur :
- Ouvrez un compte sur la plateforme du fournisseur (le lien apparaît dans le panneau)
- Générez une clé unique pour utiliser l'API de ce fournisseur et placez-la ici
- Indiquez quels modèles de ce fournisseur vous voulez :
- AUTORISER LEUR UTILISATION aux utilisateurs
- AFFICHER aux utilisateurs **
** Dans certains cas, il pourrait être intéressant d'afficher un modèle qui n'est pas ouvert à l'utilisation, mais que vous êtes prêt à activer si quelqu'un en a besoin. Parce qu'il y a certainement des modèles assez coûteux à utiliser normalement, mais qui peuvent être très utiles à activer à des moments ponctuels.
Note : à l'avenir, il est prévu d'implémenter la possibilité d'activer/désactiver les modèles PAR UTILISATEUR. De cette façon, vous aurez un meilleur contrôle sur qui consomme chaque service d'IA.
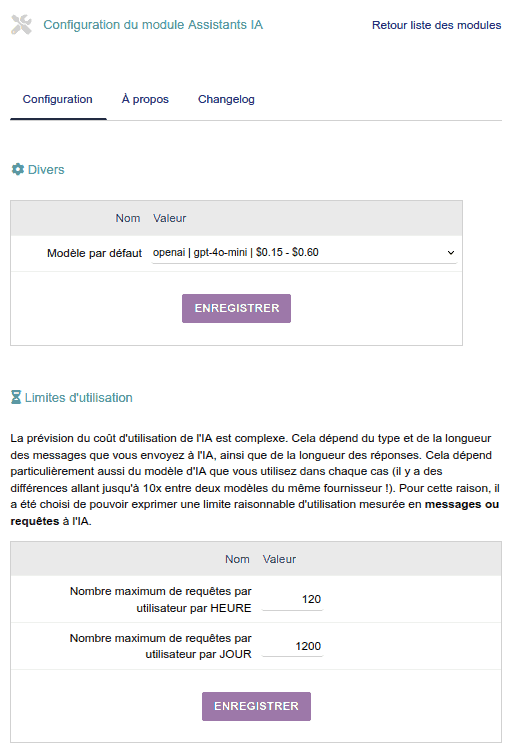
OpenAI
- C'est l'entreprise créatrice du célèbre chatGPT, qui a une particularité : elle a des modèles pour les EMBEDDINGS, qui est un service d'IA fondamental pour développer tout système de recherche sémantique, c'est-à-dire qu'un utilisateur recherche "félins" et le système lui trouve tout ce qui est lié aux chats et autres félins, même si le mot à rechercher a été mal écrit.
Ce système d'embeddings est celui qui sera utilisé pour le moteur de recherche dans l'historique des chats de chaque utilisateur, dans un avenir très proche. C'est en réalité une fonctionnalité qui sera implémentée comme OPTIONNELLE, mais elle en vaut vraiment la peine et la consommation de ce type d'IA d'embeddings est très bon marché, c'est pourquoi je vous le recommande fortement. Cela peut augmenter votre consommation d'IA d'à peine 1%, mais ce que vous obtenez en échange est radicalement bénéfique.
- Les modèles de texte ont des prix différents pour l'INPUT (ce que l'utilisateur écrit, y compris tout document qu'il joint) que pour l'OUTPUT (la réponse du modèle).
- La consommation se mesure en MILLIONS DE TOKENS. Les "tokens" sont "une partie d'un mot" et équivalent approximativement à une ou deux syllabes humaines. Ainsi, un million de tokens équivaut à plus de DEUX MILLE PAGES D'UN LIVRE moyen. L'utilisation de ces IA est donc assez économique.
Note : Dans une conversation avec l'IA, chaque nouveau message inclut tous les précédents. Cela permet à l'IA de "se souvenir" du contexte, mais augmente exponentiellement la consommation de ressources au fur et à mesure que la conversation avance, car l'IA relit tout l'historique à chaque interaction.
La recommandation est que lorsque vous devez changer de sujet, vous ouvriez une nouvelle conversation.
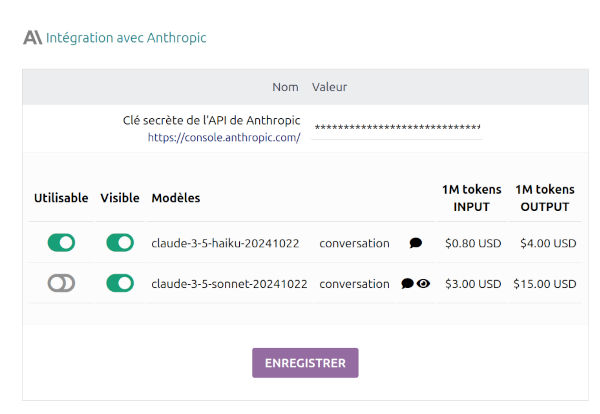
Anthropic.com
Anthropic est l'entreprise derrière les modèles Claude, qui sont à mon avis actuellement les plus compétents pour la génération de code, la traduction multilingue et la structuration de contenu textuel :
- Pour "travailler avec des textes et générer des textes", qui fonctionne comme nous sommes habitués avec ChatGPT :
Le modèle répondra en fonction de toutes les informations sur lesquelles il a été entraîné, qui ont une date limite spécifique. Au-delà de la fin de leur date d'entraînement, ces modèles n'ont pas accès aux informations actualisées.
Le modèle Haiku, qui est le plus économique, est très bon pour 90% des tâches demandées. Le modèle Sonnet est brillant mais coûte environ 4 fois plus par million de tokens.
- Pour "VOIR le contenu des images", c'est-à-dire que dans la conversation chat nous pouvons joindre des images pour qu'il les "voie" et réponde à des questions à leur sujet. Par exemple : interpréter des tableaux ou des graphiques statistiques, lire des formules chimiques, ou des problèmes mathématiques de géométrie, etc.
Cette capacité de VISION n'est disponible que dans le modèle Sonnet. Vous remarquerez que dans le module, les modèles disposant de cette capacité de VISION sont marqués d'une icône ŒIL.
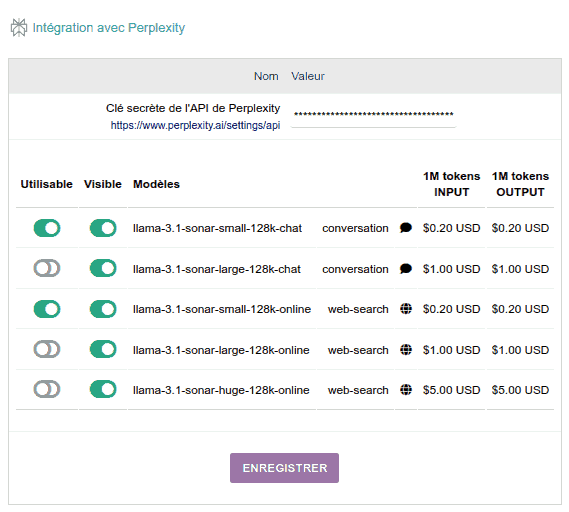
Perplexity
Perplexity est un fournisseur fabuleux de recherche sur Internet utilisant l'IA, qui intègre dans ses serveurs différents modèles open source de différents fournisseurs. Concrètement, via son API, à ce jour, il propose la famille de modèles Llama 3.1 de Meta à utiliser dans deux modalités :
- Simplement pour "chatter", qui fonctionnerait comme nous sommes habitués à ce que fait chatGPT.
C'est-à-dire que le modèle répondra sur la base de toutes les informations avec lesquelles il a été entraîné, qui ont une date limite concrète. Au-delà de la fin de sa date d'entraînement, ces modèles n'ont pas accès à des informations actualisées.
- Pour "rechercher en ligne", ce qui est assez différent : il recherche sur Internet (en utilisant Bing) des informations intéressantes pour notre question et construit une "bonne réponse".
Évidemment, la qualité de la réponse dépend beaucoup de la qualité des résultats de recherche.
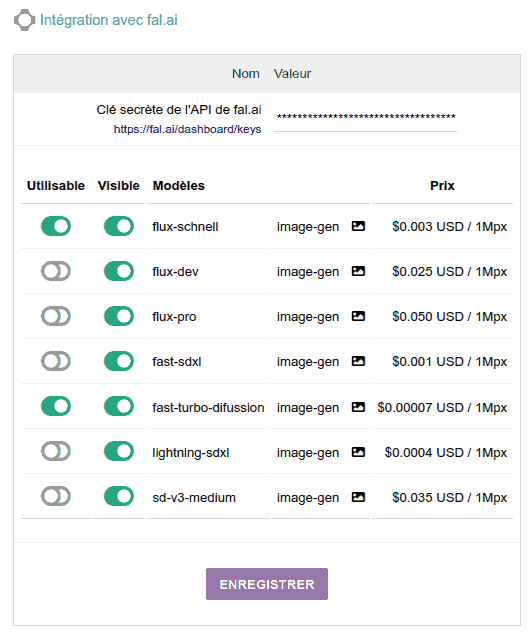
fal.ai
FAL.AI est une entreprise qui nous permet d'accéder à leurs serveurs via API pour utiliser des modèles de génération et d'édition d'images et de vidéos tiers. Plus précisément, dans ce module Dolibarr, nous utiliserons :
- La famille de modèles FLUX, apparue début 2024, qui pendant plusieurs mois a été la meilleure pour générer des images photoréalistes incluant du texte écrit (sur des panneaux, casquettes, t-shirts, voitures, etc.), principalement en ANGLAIS. Elle ne fonctionne pas aussi bien dans d'autres langues, particulièrement avec des phrases longues ou des mots qui "ne sont pas dans le dictionnaire", comme les noms d'entreprises ou de marques inconnues. En été, le modèle Ideogram 2.0 (d'une autre entreprise) a dépassé FLUX dans sa capacité à inclure du texte dans les images, et à ce jour (novembre 2024), il reste le seul qui le fait bien 80% du temps dans les langues non anglaises.
Bien que les modèles FLUX.1 aient été publiés, fal.ai ne nous propose que les modèles FLUX initiaux, qui sont toujours très bons pour générer des images avec du texte :- flux-schnell: le plus économique... environ 300 images pour 1 USD !!!!
- flux-pro: qualité maximale, bien que pour 1 USD vous ne puissiez générer "que" 20 images de super qualité
- flux-dev: le modèle intermédiaire... environ 40 images pour 1 USD - Vous pouvez également utiliser certains modèles Stable Diffusion, qui est un vétéran dans la génération d'images, notamment ces modèles :
- fast-turbo-difussion: 14 000 images pour 1 USD !!!
- sd-v3-medium: 30 images pour 1 USD.
Note: Ces modèles sont très bons avec les dessins vectoriels et artistiques, les bandes dessinées, etc. Moins avec les images photoréalistes, sauf si vous les utilisez avec LORAS. Mais cela dépasse le cadre de ce module. Si cela vous intéresse, je vous recommande d'utiliser StableDiffusion via l'interface web de fal.ai.
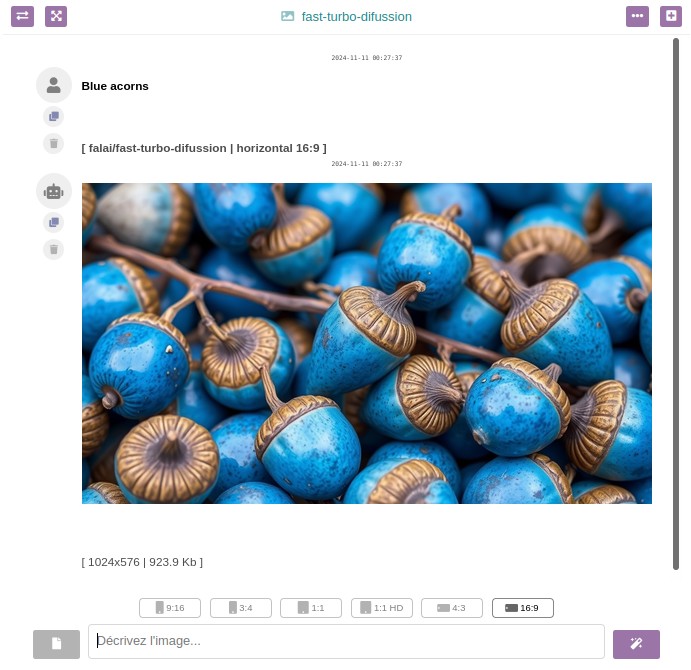
Détails techniques concernant la génération d'images
- Les images que vos utilisateurs Dolibarr génèrent dans leurs conversations seront stockées dans /documents/1/99 (où "1" est l'ID utilisateur et "99" l'ID de chaque chat). Plus tard, je mettrai en place un moyen de contrôler l'espace occupé par les images générées. Actuellement, elles occupent environ entre 500Ko et 1Mo, selon les dimensions et le modèle.
- J'ai programmé le module pour faciliter le partage d'images entre utilisateurs Dolibarr : s'ils transmettent le lien de l'image (vous pouvez l'obtenir en ouvrant l'image dans un nouvel onglet), ils peuvent télécharger l'image tant qu'ils sont connectés.
- Comme avec les modèles de chat et de recherche, différents modèles peuvent être utilisés dans la même conversation : vous pouvez passer à un modèle de génération d'images au milieu d'une conversation avec n'importe quel modèle de texte pour générer quelques images.
- Dans tous les cas, les modèles qui génèrent des images ne prennent pas du tout en compte les autres messages de cette conversation, et de même, les images générées ne sont pas prises en compte par les modèles de texte, même si elles sont dans la même conversation.
3. Converser avec une IA
En accédant à la section IA du menu supérieur, nous verrons un écran comme celui-ci, où chaque utilisateur :
- "conversera" avec les différents modèles d'IA
- interagira avec son historique de conversations
C'est une interface simple à deux panneaux :
- Panneau gauche : historique des conversations
- Panneau droit : conversation
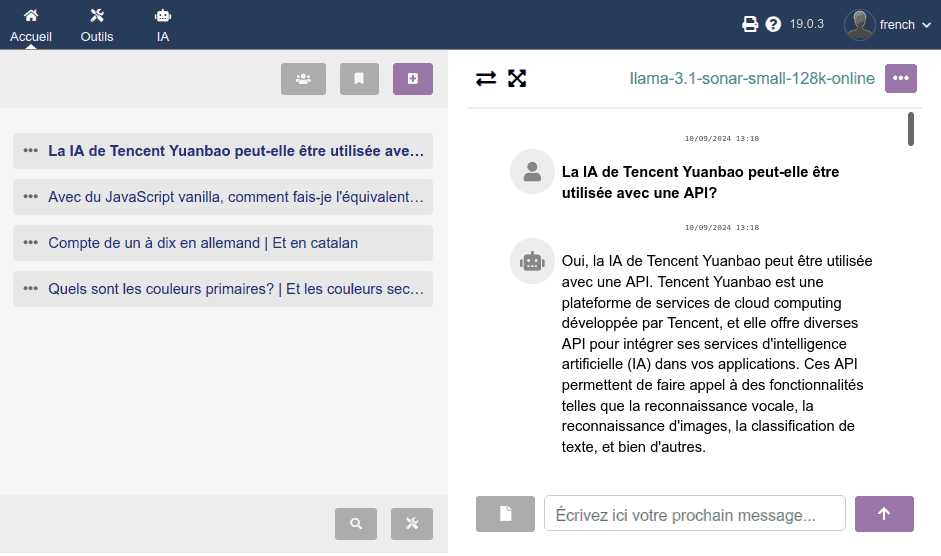
Je ne veux pas allonger ce guide inutilement, je pense que presque toutes les fonctions et boutons sont assez évidents, donc je ne commenterai que les plus pertinents. Si vous pensez que quelque chose n'est pas répondu, veuillez laisser un commentaire tout en bas pour que je complète cette information ici. Merci !
Éléments graphiques
- Les boutons en niveaux de gris sont des boutons de fonctions prévues pour être implémentées prochainement. Ils seront activés dans les mises à jour successives.
- La façon basique de travailler est d'appuyer sur le bouton "+" pour commencer une nouvelle conversation, ou de cliquer sur n'importe laquelle de l'historique pour la continuer.
- Dans le panneau droit, vous avez un bouton pour masquer le panneau gauche.
- Dans le panneau droit, vous avez un bouton pour "maximiser" la zone de chat :
1. cache le panneau gauche
2. cache la barre supérieure des menus de Dolibarr
3. maximise votre fenêtre de navigateur - Lorsque vous rédigez un nouveau message, vous pouvez utiliser la touche ENTRÉE pour ajouter des sauts de ligne, et vous pouvez utiliser la touche TAB pour positionner le focus sur le bouton ENVOYER MESSAGE. De cette façon, vous pouvez maintenir une conversation sans lever la main du clavier.
Options d'un chat
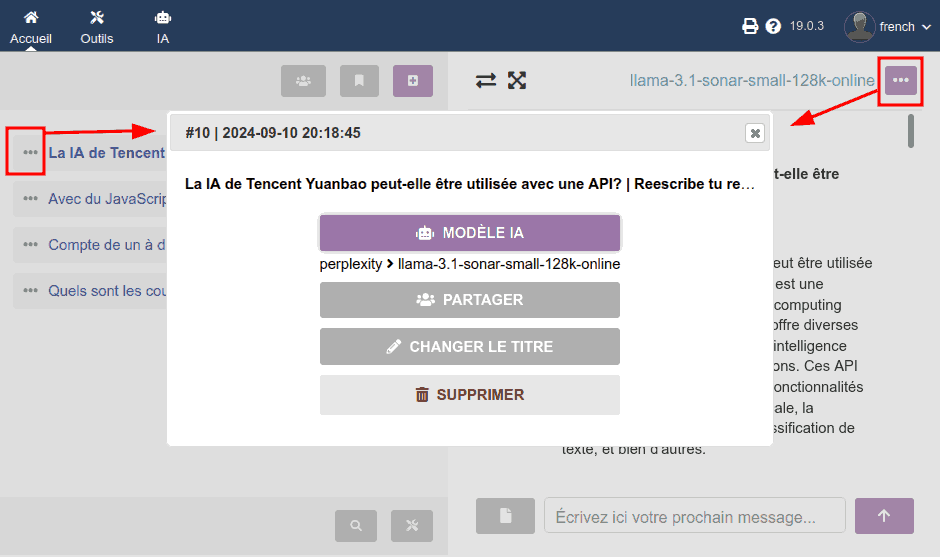
En cliquant sur n'importe quelle icône du type trois points (···), une fenêtre modale (popup) apparaît avec :
- l'ID numérique de la conversation
- la date de début de la conversation
- le modèle d'IA actif ou utilisé dans le dernier message de ce chat (rappelez-vous que dans chaque message d'un même chat, vous pouvez utiliser différents modèles !)
- bouton pour partager (prochainement)
- bouton pour changer le titre dans l'historique (prochainement)
- bouton SUPPRIMER (fonctionne déjà !), qui vous demandera confirmation avant de supprimer
Sélection du modèle d'IA
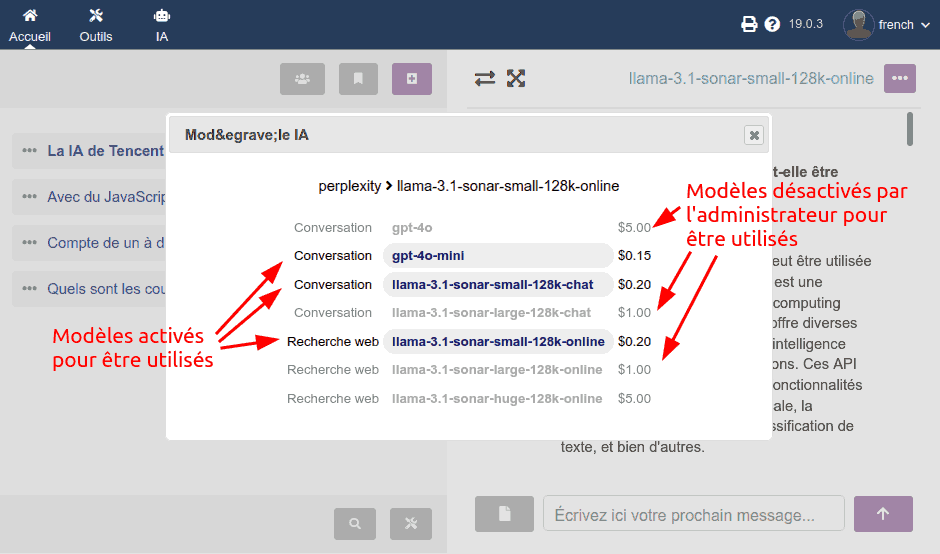
En appuyant sur le bouton précédent "Modèle IA", un second cadre de dialogue apparaît :
- avec la liste des modèles que l'administrateur a configurés comme VISIBLES dans le panneau d'administration
- apparaissent désactivés les modèles qui ont été configurés comme VISIBLES mais NON UTILISABLES
- j'ai décidé d'inclure le prix pour faire participer les utilisateurs finaux à la différence (grande !) de prix entre l'utilisation d'un modèle ou d'un autre, et encourager une utilisation responsable
Note : pour le moment, il n'y a que des modèles de génération de texte, mais prochainement il y aura des modèles de génération d'images, de transcription audio, etc.
Prochainement
Plus d'intégrations avec des fournisseurs d'IA
Si vous avez suivi cette révolution technologique que nous vivons avec les "IA génératives", vous savez que chaque semaine apporte des nouveautés. Donc ma volonté est d'ajouter l'intégration de plus en plus de modèles et de fournisseurs de modèles. L'idée est que depuis un même panneau (depuis notre Dolibarr) nous ayons une base solide à partir de laquelle bénéficier de ces IA, dans un environnement multi-utilisateurs.
- transcription multi-langue d'audios (avec Whisper d'OpenAI)
- génération de vidéos (cela va exploser avant la fin de 2024 !)
- génération audio à partir de texte (OpenAI, Azure Cognitive Services ?)
Interagir avec la base de données de Dolibarr
De plus, évidemment, je suis déjà en train de voir comment on pourrait intégrer dans ces conversations avec l'IA l'accès aux données stockées dans notre base de données, que ce soit pour :
- analyser les tendances
- résumer ou récupérer des données de clients, projets, produits, etc.
- comparer des produits, des commandes, etc...
Il ne fait aucun doute que l'IA peut nous être très utile pour interagir avec nos propres données. Je travaillerai dessus. Si vous avez une référence utile de personnes qui ont déjà avancé sur ce sujet, même si c'est dans un autre ERP, s'il vous plaît, laissez-moi la référence dans les commentaires !
Fonctions d'IA contextuelles
J'aimerais aussi pouvoir ajouter des "boutons rapides d'assistance" dans les différentes listes et fiches des objets de Dolibarr, et dans les éditeurs de texte, avec des prompts pré-enregistrés du type :
- traduire vers la langue X
- corriger grammaticalement et améliorer une rédaction (email, réponse de ticket, etc.)
- résumer un tableau de données (de factures d'un client, de production, etc.)
Añada su comentario: