User Manual for the AI Assistants Module for Dolibarr
17 minutos de lectura
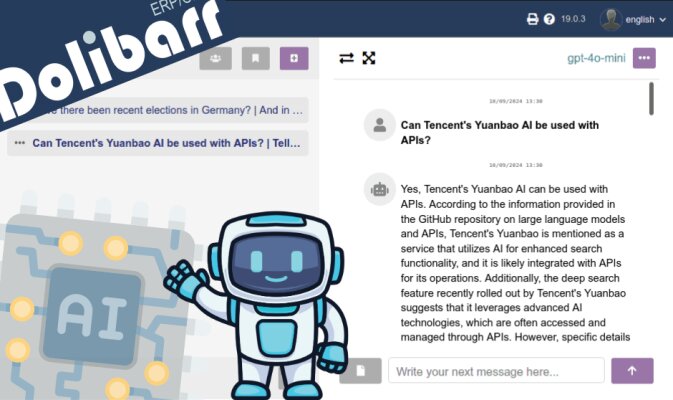
This module, which you can purchase from Dolistore, offers you the ability to use many generative AI models directly from your own Dolibarr installation, consuming the minimum through the APIs of different providers, instead of subscribing to fixed monthly payments for each employee in your company.

Index
If you are not an administrative user of your Dolibarr, you can skip to point 3 of this manual.
- Installation Process
- Integration with AI Providers
- OpenAI (text generation)
- Anthropic.com (text generation with vision)
- Perplexity (text generation and online search)
- Fal.ai (image generation with FLUX & StableDifussion)
- Conversing with an AI
- Coming Soon
- Access to DEMO
1. Installation Process
First, as usual for installing any Dolibarr module:
- Go to the Configuration section
- Go to Modules
- Go to the Install an external module tab, and there you upload the ZIP of the module or its update
- Return to the Available modules tab
- Filter by Origin: "External - IMASDEWEB"
- Activate the module
- Click on the Configuration icon
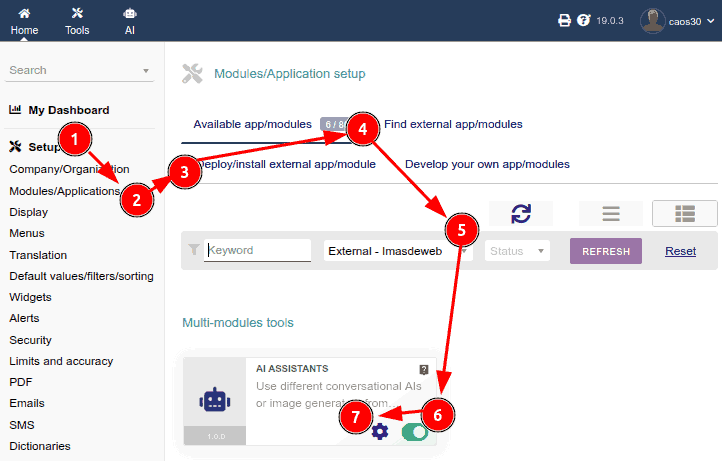
In a first Miscellaneous section, we can configure things like the "Default model". This will be the model with which a chat will be initialized when the system has no information in the user's session variable about the last model they used.
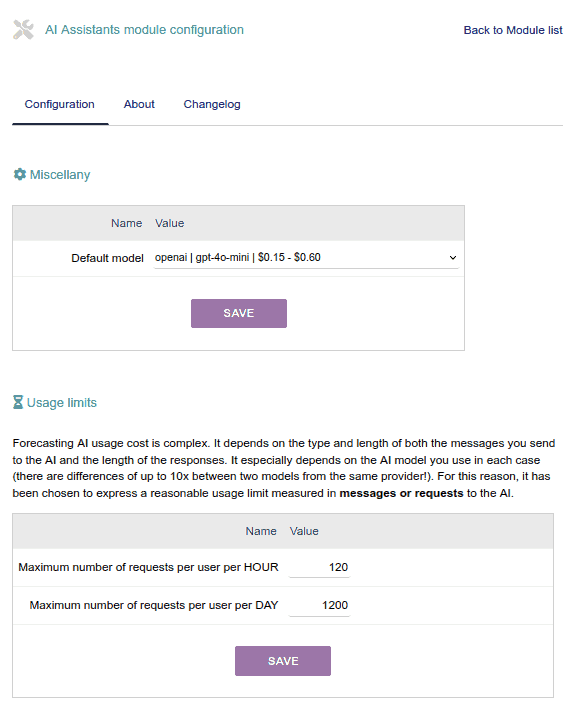
Usage Limit per User
You can configure the usage limit per user, both per hour and per day:
- Every time a user makes an AI request, the system counts how many requests they have made in the last 60 minutes, and also in the last 24 hours. And if either of these values exceeds the corresponding limit, then it displays a message to the user encouraging them to try again later.
- Depending on the size of your organization and the type of use that your users/employees will make or need to make, it will be convenient for you to configure these two parameters differently.
For example, maybe you don't want a user to be able to make very intensive use of AI (generating texts, images, etc.) for a few hours. You can then configure a high hourly limit (for example, one request every 10 seconds would be 6 per minute and 360 per hour. But since you don't want this to encourage excessive use, you could set a limit of only 1400 every 24 hours. This way, you would allow intensive uses of AI, while ensuring some control over prolonged abusive use.
2. Integration with AI Providers
This is the most interesting part and the one that will vary most frequently with each update. Over the coming months, more and more integrations with new providers or new models from the same providers will be added. So, if you want to make the most of it, it would be recommended to update regularly.
To configure each provider:
- Open an account on the provider's platform (the link appears in the panel)
- Generate a unique key to use the API of this provider and place it here
- Indicate which models from this provider you want to:
- ALLOW THEIR USE to users
- DISPLAY to users **
** In some cases, it might be interesting to display a model that is not open for use, but that you are willing to activate if someone needs it. Because there are certainly models that are quite expensive to use normally, but can be very useful to activate at specific times.
Note: in the future, it is planned to implement the possibility of activating/deactivating models PER USER. This way, you will have better control over who consumes each AI service.
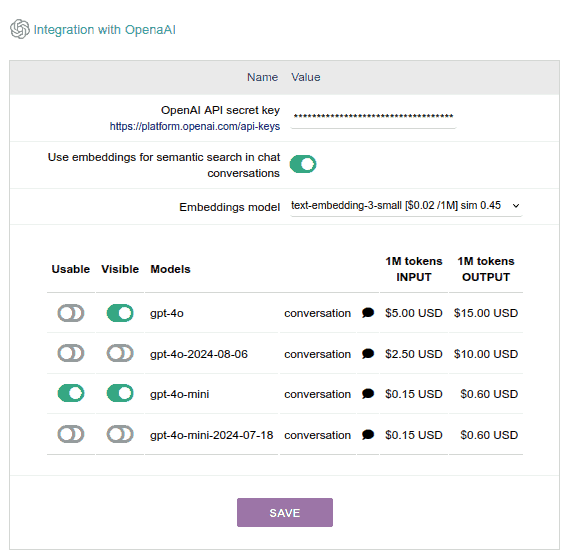
OpenAI
- This is the company that created the famous chatGPT, which has a particularity: it has models for EMBEDDINGS, which is a fundamental AI service to develop any semantic search system, that is, a user searches for "felines" and the system finds everything related to cats and other felines, even if the word to search was misspelled.
This embeddings system is the one that will be used for the search engine in the chat history of each user, in the very near future. It's actually a feature that will be implemented as OPTIONAL, but it's really worth it and the consumption of this type of AI embeddings is very cheap, which is why I highly recommend it. It can increase your AI consumption by barely 1%, but what you get in return is radically beneficial.
- The text models have different prices for INPUT (what the user writes, including any document they attach) than for OUTPUT (the model's response).
- Consumption is measured in MILLIONS OF TOKENS. "Tokens" are "a part of a word" and roughly equivalent to one or two human syllables. Thus, a million tokens is equivalent to more than TWO THOUSAND PAGES OF AN AVERAGE BOOK. The use of these AIs is therefore quite economical.
Note: In a conversation with the AI, each new message includes all the previous ones. This allows the AI to "remember" the context, but exponentially increases resource consumption as the conversation progresses, as the AI rereads the entire history with each interaction.
The recommendation is that when you need to change the subject, you open a new conversation.
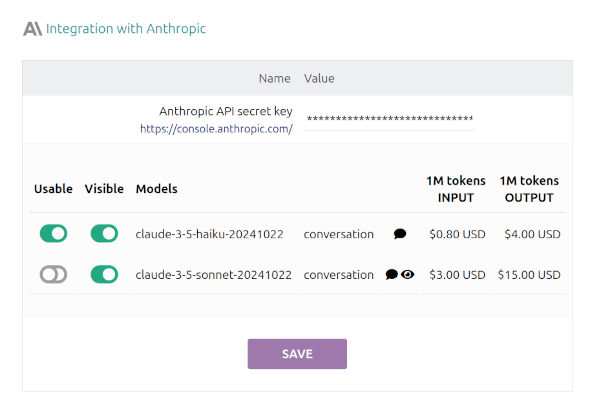
Anthropic.com
Anthropic is the company behind the Claude models, which in my opinion are currently the most competent for code generation, multilingual translation, and text content structuring:
- For "working with texts and generating texts", which works as we are accustomed to what ChatGPT does:
The model will respond based on all the information it has been trained on, which has a specific cut-off date. Beyond the end of their training date, these models do not have access to updated information.
The Haiku model, which is the most economical, is quite good for 90% of the tasks requested. The Sonnet model is brilliant but costs about 4 times more per million tokens.
- For "SEEING image content", meaning that in the chat conversation we can attach images for it to "see" and respond to queries about them. For example: interpreting statistical tables or graphs, reading chemical formulas, or geometric mathematical problems, etc.
This VISION capability is only available in the Sonnet model. You'll notice that in the module, models with this VISION capability are marked with an EYE icon.
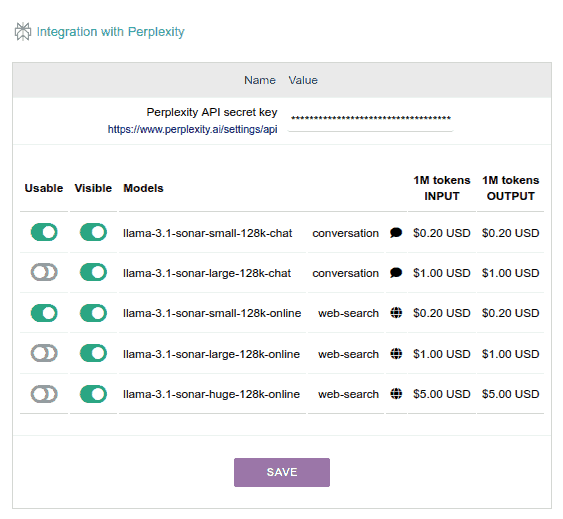
Perplexity
Perplexity is a fabulous provider of Internet search using AI, which integrates different open source models from different providers on its servers. Specifically, through its API, to date, it offers the Llama 3.1 family of models from Meta to be used in two modalities:
- Simply to "chat", which would work as we are used to chatGPT doing.
That is, the model will respond based on all the information with which it has been trained, which has a specific cut-off date. Beyond the end of its training date, these models do not have access to updated information.
- To "search online", which is quite different: it searches the Internet (using Bing) for interesting information for our question and builds a "good answer".
Obviously, the quality of the answer depends a lot on the quality of the search results.
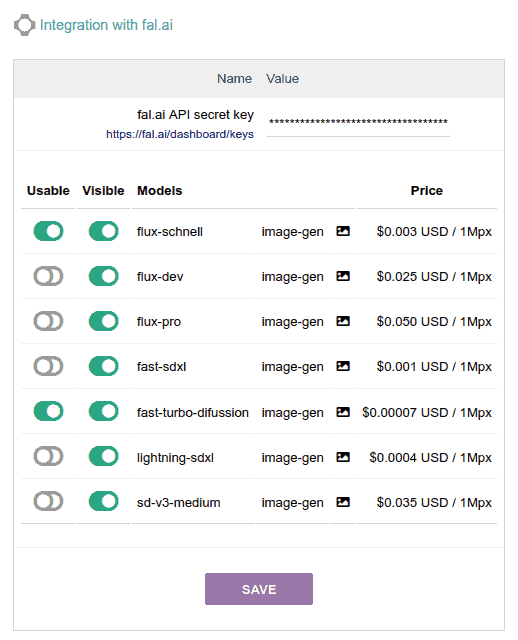
fal.ai
FAL.AI is a company that allows us to access their servers via API to use third-party image and video generation and editing models. Specifically, in this Dolibarr module, we will be using:
- The FLUX family of models, which appeared in early 2024 and for several months were the best at generating photo-realistic images that include written text (on signs, caps, t-shirts, cars, etc.), although mainly in ENGLISH. It doesn't perform as well in other languages, especially with long phrases or words that "aren't in the dictionary," like unknown company names or brands. In summer, the Ideogram 2.0 model (from another company) surpassed FLUX in its ability to include text in images, and as of today (November 2024), it remains the only one that does it well 80% of the time in non-English languages.
Although FLUX.1 models were released, fal.ai only offers us the initial FLUX models, which are still very good at generating images with text:- flux-schnell: the most economical... about 300 images per $1 USD!!!!
- flux-pro: maximum quality, although for $1 USD you can generate "only" 20 super-quality images
- flux-dev: the intermediate model... about 40 images per $1 USD - You can also use some Stable Diffusion models, which is a veteran in image generation, specifically these models:
- fast-turbo-difussion: 14,000 images per $1 USD !!!
- sd-v3-medium: 30 images per $1 USD.
Note: These models are very good with vector drawings and artistic drawings, comics, etc. Not so much with photo-realistic images unless you use them with LORAS. But this is beyond the scope of this module. If you're interested in this, I recommend using StableDiffusion through fal.ai's web interface.
Technical details regarding image generation:
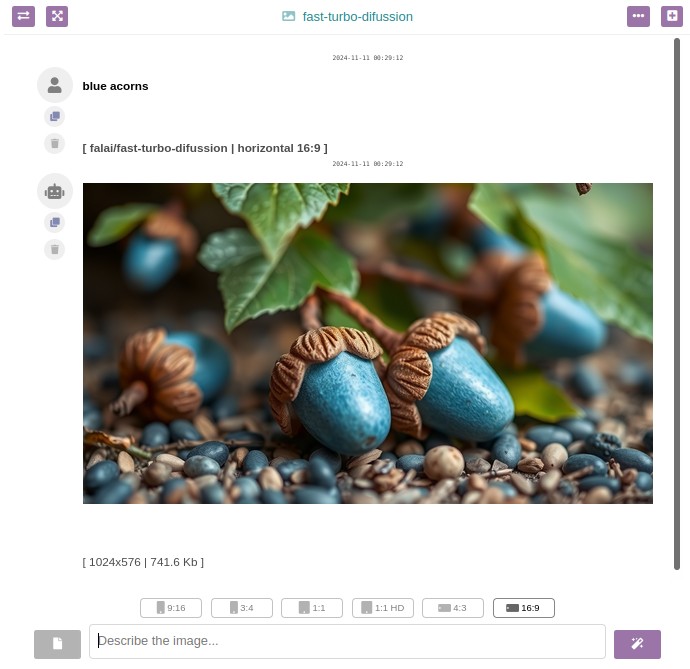
- The images that your Dolibarr users generate in their conversations will be stored in /documents/1/99 (where "1" is the user ID, and "99" is the ID of each chat). Later, I will implement some way to control how much space the generated images occupy. Currently, they take up approximately between 500Kb and 1Mb, depending on the dimensions and model.
- I have programmed the module to make it easy to share images between Dolibarr users: if they pass the image link (you can get it by opening the image in a new tab), they can download the image as long as they are logged in.
- Just like with chat and search models, different models can be used in the same conversation: that is, you can switch to an image generation model mid-conversation with any of the text models to generate some images.
- In any case, the models that generate images don't take into account the other messages in that conversation at all, and similarly, the generated images are not taken into account by the text models, even if they are in the same conversation.
3. Conversing with an AI
When accessing the AI section from the top menu, we'll see a screen like the following, which is where each user will:
- "converse" with different AI models
- interact with their conversation history
It's a simple two-panel interface:
- Left panel: conversation history
- Right panel: conversation
I don't want to unnecessarily lengthen this guide, I think almost all functions and buttons are quite obvious, so I'll only comment on the most relevant. If you think something is not answered, please leave a comment at the bottom so I can complement that information here. Thank you!
Graphic Elements
- Grayscale buttons are buttons for functions planned to be implemented soon. They will be activated in successive updates.
- The basic way of working is by pressing the "+" button to start a new conversation, or by clicking on any from the history to continue with it.
- In the right panel, you have a button to hide the left panel.
- In the right panel, you have a button to "maximize" the chat area:
1. hides the left panel
2. hides the top Dolibarr menu bar
3. maximizes your browser window - When writing a new message, you can use the ENTER key to add line breaks, and you can use the TAB key to position the focus on the SEND MESSAGE button. This way you can maintain a conversation without lifting your hand from the keyboard.
Chat Options
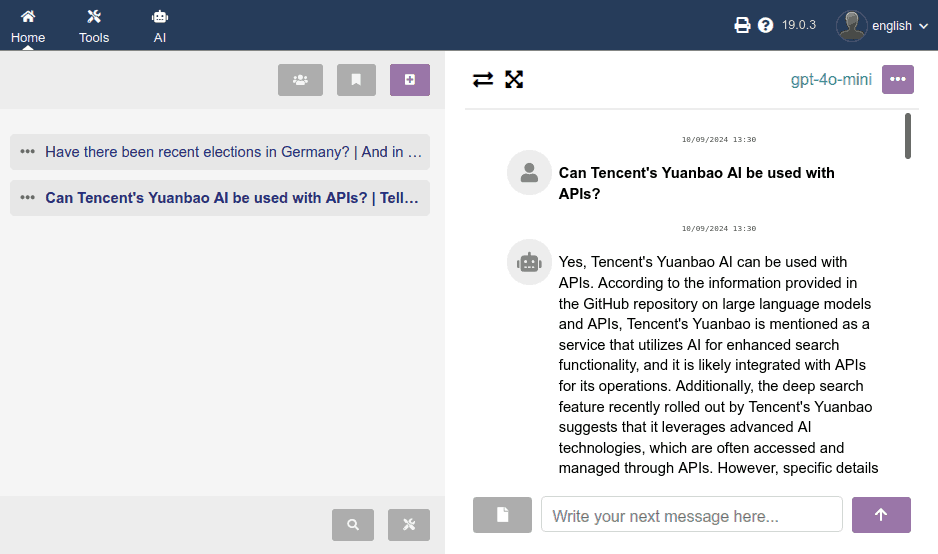
When clicking on any three-dot icon (···), a modal window (popup) emerges with:
- the numeric ID of the conversation
- the start date of the conversation
- the AI model active or used in the last message of that chat (remember that in each message of the same chat you can use different models!)
- button to share (coming soon)
- button to change the title in the history (coming soon)
- DELETE button (already working!), which will ask for confirmation before deleting
AI Model Selection
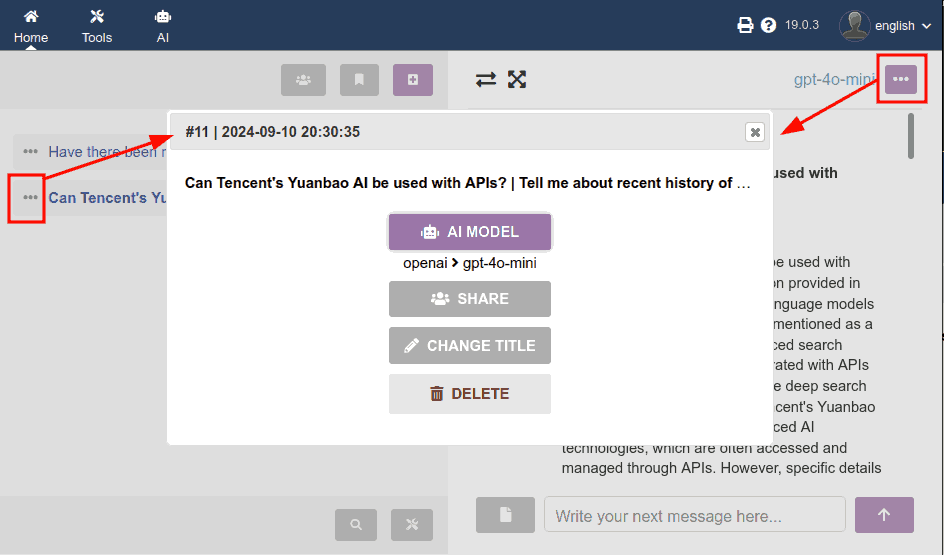
When clicking on the previous "AI Model" button, a second dialog box emerges:
- with the list of models that the administrator has configured as VISIBLE in the admin panel
- models appear disabled that were configured as VISIBLE but NOT USABLE
- I decided to include the price to make end users aware of the (big!) price difference between using one model or another, and encourage responsible use
Note: right now there are only text generation models, but soon there will be image generation models, audio transcription, etc.
Coming Soon
More integrations with AI providers
If you've been keeping up with this technological revolution we're experiencing with "generative AIs", you know that new developments appear every week. So my intention is to add integration with more and more models and model providers. The idea is that from a single panel (from our Dolibarr) we have a solid base from which to benefit from these AIs, in a multi-user environment.
- multi-language audio transcription (with OpenAI's Whisper)
- video generation (this is going to explode before the end of 2024!)
- audio generation from text (OpenAI, Azure Cognitive Services?)
Interacting with the Dolibarr database
Additionally, obviously, I'm already looking at how access to data stored in our database could be integrated into these conversations with AI, whether to:
- analyze trends
- summarize or retrieve data on customers, projects, products, etc.
- compare products, orders, etc...
There's no doubt that AI can be very useful for interacting with our own data. I'll be working on it. If you have any useful references from people who already have something advanced in this, even if it's in another ERP, please leave me the reference in the comments!
Contextual AI functions
I would also like to be able to add "quick assistance buttons" in the different listings and sheets of Dolibarr objects, and in text editors, with pre-recorded prompts such as:
- translate to language X
- grammatically correct and improve a draft (email, ticket response, etc.)
- summarize a data table (of a customer's invoices, production, etc.)
Añada su comentario: